
It’s been a while! I have been very busy with university for the past few months. Since I just ended the semester, I’d like to do these paper reviews more regularly. So stay tuned for more.
Today, we will be reading What Languages are Easy to Language-Model? A Perspective from Learning Probabilistic Regular Languages. I am currently working in multilingual language model in my internship, and I hope this paper will shed a light into the difference languages make in the development of LLMs… or at least that was my impression is before I read the paper.
After reading, I realize that this paper is mostly about finding a mathematical formalization of how well language models (LM) learn a certain distribution. Despite it being slightly different from what I expected, there is still a trove of interesting insights here.
Summary
This paper revolves around understanding the limits of LMs. Remember that LMs are just models that learn the representations of a certain token distributions. These distributions vary from languages to languages, and applications to applications. For example, a protein language model would have different distribution as compared to an English literary language model, obviously. However, despite the advancement of LMs, there is no formal guarantee on which distribution they can or cannot represent. This paper aims to provide that guarantee, or at least determine which distribution is easier to represent than others.
The authors extensively used Deterministic Probabilistic Finite-State Automata (DPFSA) to simulate language models, and then proved that any neural LMs that exactly matches DPFSA of rank must have hidden-state dimension , where (Theorem 3.1). Any lower than , the neural LMs won’t be able to represent the distribution properly.
Empirically, the authors generate random DPFSA of controller size and rank, then train RNN and Transformers on the sampled string, and measure their performance by calculating the KL-divergence to the true DPFSA distribution.
Neural LMs vs PFSAs
Before we dive into DPFSAs, let’s recall the two ends of the language modeling spectrum:
- Traditional automata and n-grams
- n-grams LMs predict the next token by a lookup table over the last tokens.
- Probabilistic Finite State Automata (PFSAs) generalizes this through weighted transitions that emit symbols with certain probabilities.
- Modern LLMs
- RNNs, LSTMs, and Transformers compute a continuous hidden vector from the previous tokens.
- A final linear layer and softmax turns that into the next-token probabilities.
There has been a long-standing softmax bottleneck concern where low-rank is unable to express all possible conditional distributions. To validate this, we need to compare with an automata with well-defined distribution, such as DPFSAs.
DPFSAs
A DPFSA is a PFSA with at most 1 outgoing transition for each state-symbol pair. More precisely:
- You have an alphabet and finite set of states .
- From each and , at most one transition exists, where is the transition probability.
- This results in determinism where each input string follows exactly one path through the automaton, resulting in a unique probability value.
Furthermore, a minimal DPFSA has no redundant and unreachable state. So each of its states are used.
Using DPFSAs as Softmax-Layer LM
To bridge DPFSA and neural LMs, we observe that the DPFSA’s next symbol distribution can be written exactly as:
This is equation(3) in the paper, where:
- is the one-hot state of the automaton after seeing prefix .
- collects all transition and EOS logits. Note that this output matrix has the full-rank , but further in the paper, we often do not use the full rank, and refer .
Combining Everything
With this formulation in hand, we can determine that a minimal DPFSA one-hot vector spans the entire . But multiplying by a rank matrix can only hit an dimensional subspace. Therefore, we get our very important core theory:
Theorem 3.1 (rephrased)
If a minimal DPFSA has rank then any representation-based neural LM that exactly matches its distribution must use at least dimensions in its final representation.
The best thing is that this theorem is architecture-agnostic. It holds for RNNs, LSTMs, Transformers, etc, as long as it ends in a linear + softmax layer.
Empirical Validation
To validate this theorem, the authors generate DPFSAs with controlled and rank by sampling a Gaussian matrix. Each automaton serves as “text generator” generating some thousands of sample strings. Then they trained RNNs and Transformers of various hidden sizes on those samples and measure the KL-divergence , where is DPFSA distribution and is neural LMs.
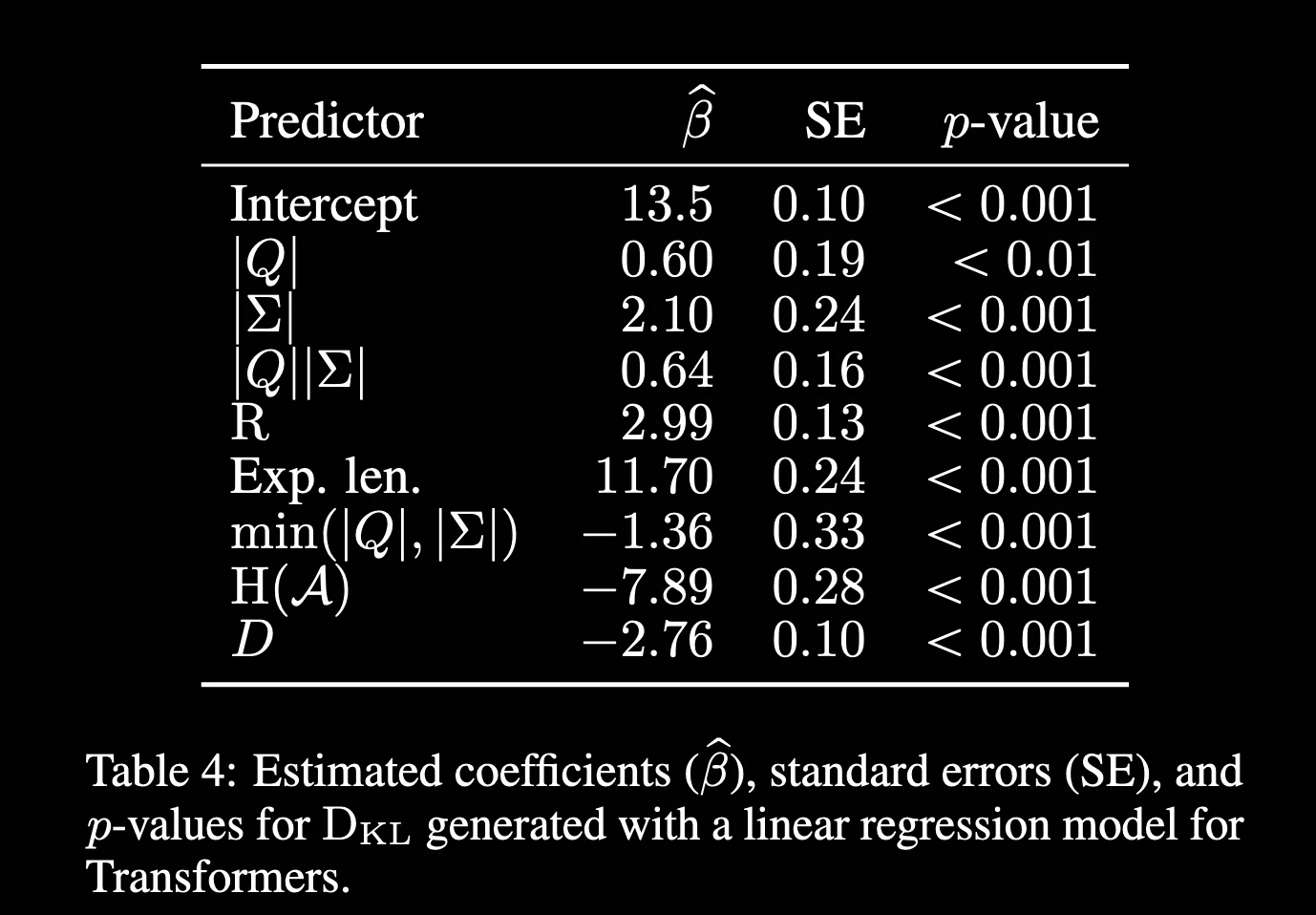
Here are the key findings (Table 4 in the paper):
- As soon as , KL-divergence spikes, confirming that is indeed the lower bound.
- More states , symbols or expected length will widen the KL-divergence gap, but rank is the most dominant factor.
- Most interestingly, automata with higher randomness (entropy) are easier to approximate by neural LMs.
The authors then did comparisons between RNNs and Transformers, where they found that RNNs generally found better distribution, showing the capabilities of RNNs in modeling formal languages right off the bat, while transformers still need careful language-specific hyperparameter tuning. The predictors in Table 4 also have different significance between transformers and RNNs. For example, are strong predictors of transformers, but not RNNs.
Final Words
This paper delivered a clean, architecture-agnostic lower bound on neural LM capacity in representing distributions, fully backed up by empirical evidence across two different architectures.
My Thoughts
Definitely not what I expected from the title, but formalization papers are always very rewarding to pick apart and understand slowly. While I more or less understand the theory behind this paper, there are some lingering questions on the applications.
- How do we find the distribution of real languages? How do we apply DPFSA in this case?
- We found the lower bound of representation, but this does not quantify how good the representation is. Is there a metric to measure this?
- Since DPFSA has fixed and , how does this translate to real languages where there are increasing vocabulary bank? Things like slangs, memes, etc always come up with new words.
All in all, this paper is a good first dip into optimizing small models. I get to apply a lot of my previous courses in Neural Network and Deep Learning, Statistics, and Artificial Intelligence into understanding this paper in-depth. Good read!